Pythonを使って、ニュースサイトの記事タイトル名を取得する方法を纏めてみます。
今回使うニュースサイトは東海地方のニュースがまとまったロキポのニュースページを使います。
(このページにした意味は特にありません)
このトップページから、ニュースの記事名と、記事のURL、記事の発行元を抽出します。
必要なライブラリ
import requests
from bs4 import BeautifulSoup as bs
import pandas as pdまずは requests 。これは、url 先の情報を取得してくれるライブラリです。
天気API を使う方法を紹介した記事でも登場しました。

そして、BeautifulSoup というライブラリ。
requests は、url 先の情報をHTMLの文字列で取得してくるだけなので、それをBeautifulSoupが解析してくれます。
名前の由来は、サイトのHTMLタグの海(スープ)から、必要な情報をうまく抽出して綺麗なスープを作る、みたいな感じだったと記憶してます(違うかな)
pandas は、今回は取ってきた情報を csv ファイル形式にして保存するために使います。
csvファイル形式にすれば、取得した情報をエクセルなどで読むことができます。
まずはサイトのソースを見てみる
まずはソース見てみる必要性があります。
といっても、自分自身そこまで HTML には詳しくありませんが。
データを取得したいページにて、右クリックして検証を選択することでページのソースを見れます。
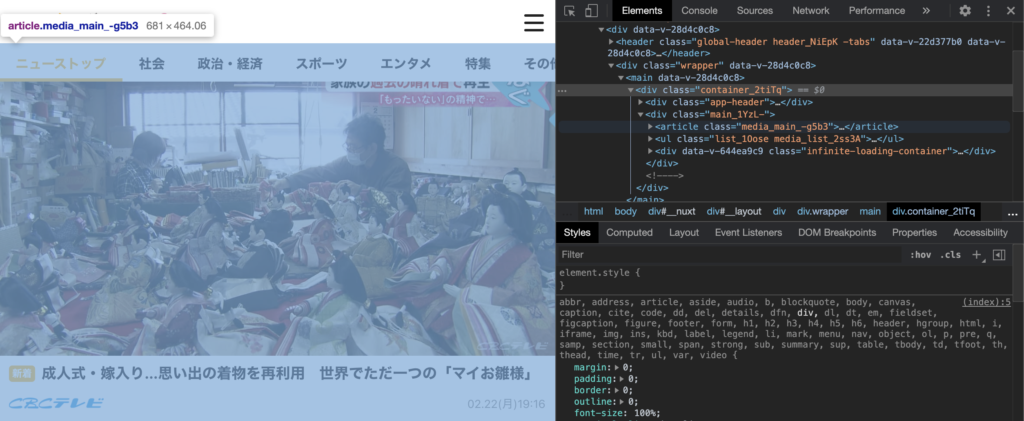
このページでは、「article」というタグに、それぞれの記事が入っているようです。
とり会えず、article タグの情報を全て取得してみます。
BeautifulSoupを使って記事情報の取得
それでは、早速やってみましょう。
まずは requests を使って、 url 先の情報を取得します。
url = 'https://locipo.jp/article'
res = requests.get(url)requests.get で得た情報を、変数 res で受けます。
次にこの情報を BeautifulSoup (ここでは bs としてます) を使って解析します。
解析した結果は変数 soup で受けます
soup = bs(res.text)res.text のままではただの文字列だったものを、soup で意味を持って情報を取得できるものに変換するという感じです。
次に article というタグ内に記事情報がありそうだということをみたので、find_all()メソッドを用いて、article の要素を全て取得します。
articles = soup.find_all('article')
print(len(articles)) #20find_all()メソッドを用いて得た結果はリスト形式で帰ってきますので、len()を用いて、要素数をみれます。
今回は20個の記事を取得しました。
リストarticles の最初の要素を見て見ましょう。
articles[0].text
#新着勝負強さは健在…球界最年長の中日・福留がDeNAとの二軍練習試合で2安打2打点 石川昂弥も猛アピール02.22(月)20:07「.text」を使うことで、そのタグ内の文字情報を全て得ることができます。
今回取得できた情報は
「新着勝負強さは健在…球界最年長の中日・福留がDeNAとの二軍練習試合で2安打2打点 石川昂弥も猛アピール02.22(月)20:07」

しかし、今回は、「新着というトップ記事にでる文字 + 記事名 + 日にち時間」が同時に得られています。
これで良い場合もあるかもしれませんが、なるべく記事名だけ得たいという場合が多いでしょう。
そこで、より絞り込んでテキスト化する必要があります。
print(articles[0]) で、詳しく内容を見てみると、記事名は、
print(articles[0])
#~省略~
#<h2 class="title_13taR">勝負強さは健在…球界最年長の中日・福留がDeNAとの二軍練習試合で2安打2打点
#石川昂弥も猛アピール</h2>
#~省略~のように、タイトルは h2 タグで囲まれています。なので、、
title0 = articles[0].find('h2').text
print(title0)
#'勝負強さは健在…球界最年長の中日・福留がDeNAとの二軍練習試合で2安打2打点 石川昂弥も猛アピール'とすると、記事名だけ取得することができます。
では、2番目の記事以降も。。
articles[1].find('h2').text
AttributeError: 'NoneType' object has no attribute 'text'とやると、エラーが出てしまいました。要するに、2番目以降のarticle には、h2 タグが内容です。
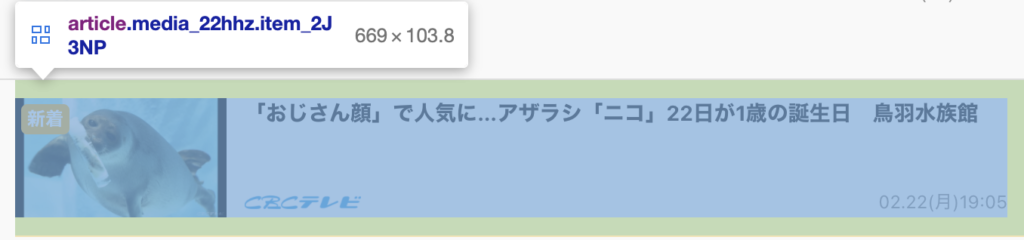
最初の記事は、ページトップに大きめに表示され、それ以降は少し小さめに表示されるという、サイトでよくある表示の仕方ですが、
それによってフォーマットも変わってしまいます。
これも、ソースをみて、タイトルがどのタグ内にあるかを確認する必要があります。
articles[1].find('h3').text
#'成人式・嫁入り…思い出の着物を再利用\u3000世界でただ一つの「マイお雛様」'最初の記事以外は、h3 タグに記事名が入っているようです。
最初の記事以外をまとめると、、
titles = [article.find('h3').text for article in articles[1:]]
titles
'''
['新着勝負強さは健在…球界最年長の中日・福留がDeNAとの二軍練習試合で2安打2打点 石川昂弥も猛アピール02.22(月)20:07',
'成人式・嫁入り…思い出の着物を再利用\u3000世界でただ一つの「マイお雛様」',
'「おじさん顔」で人気に…アザラシ「ニコ」22日が1歳の誕生日\u3000鳥羽水族館',
'物流会社の倉庫が全焼…火を使った作業が原因か\u3000愛知・武豊町',
'リコール署名偽造問題…高須院長会見「こんな貧乏たらしいことするわけない」',
'バイトの受注したとされる社長「闇は深いと思いますよ…」リコール署名の偽造疑惑 見えてきた不正の構図',
'大村・愛知県知事のリコール署名偽造、リコール運動の事務局が発注か',
'東日本大震災から10年\u3000小学校で命を守る避難訓練\u3000三重・尾鷲市',
'中部空港の「フライト・オブ・ドリームズ」有料エリア、来月末で営業終了へ',
'福留二番起用で打線に厚みを!井端、本音トークでドラゴンズ戦力チェック!',
'ワクチン接種後の副反応は…病院長「発熱は78人中1人。診療に影響なし」接種によって「社会の免疫を」',
'愛知\u3000緊急事態宣言「2月28日まで」\u3000政府に解除要請\u3000',
'リコール運動主導の高須院長「佐賀は1度ヘリで行った事あるだけ 何の関係もない」不正署名への関与否定',
'起こされ「うるせぇ」と蹴りも…障害者施設での虐待事件 元職員は「注意聞き入れぬ入所者に立腹し暴力」か',
'名古屋の先行接種…軽症ながら4人副反応の疑い\u3000三重ではLINEでアンケート',
'下着などがイヤリングやヘアバンドに…廃棄予定だった下着や部屋着を専門学生がリメイク 女子高生に贈呈',
'黒煙立ち上り屋根が崩落…鉄骨平屋建ての倉庫・約1千平米が全焼 プラスチック製のパレットなど保管',
'自殺志願の女性と男をつないだのは「ツイッター」連絡取り合い2日後に嘱託殺人未遂の疑い 男は金銭目的か',
'ドラゴンズ“立浪塾”が熱い!根尾そして岡林ら“塾生”たち覚醒の手応え',
'「落合ノック」から10年 ドラゴンズ沖縄キャンプに見る令和時代の指導者像~最強の内野守備を目指して~']
'''
print(len(titles)) #19こんな感じでかけます。うまく全ての記事名が得られています。「\u3000」という文字列は全角スペースを表します。
最初の記事のタイトル「title0」をinsertすれば、全ての記事名を一つのリストにできます。
titles.insert(0,title0)記事の発行元を取得する。
今度は記事の発行元を取得してみます。
このサイトは、中京テレビ、東海テレビ、CBCテレビ、テレビ愛知 という4社が記事を制作しており、どの会社が作った記事かを取得してみます。
どこの会社が作った記事かは、img タグの alt 属性が持っています。
articles[0].find_all('img')
[<img alt="" class="eyecatch_wN9Ea" src="https://dophkbxgy39ig.cloudfront.net/store/articles/54789228/original-83d2b3819374a34ee797c895fc7c0fa4.jpg"/>,
<img alt="東海テレビ" src="https://service.locipo.jp/images/logo_tohkaitv.png"/>]find_all('img') をすると、二つの要素が得られます。
一つ目は、記事のメイン画像で、二つ目は、記事制作会社のロゴ画像のようです。
この二つ目の画像要素が、alt 属性に社名を持っているようです。
なので、二つ目の画像の alt 属性を得られば、どこの会社制作の記事かがわかります。
articles[0].find_all('img')[1].get('alt')
#'東海テレビ'属性の内容は get() メソッドで取得可能です。
二つ目の画像要素に、社名を持っているのは、トップ記事も後続の記事も同様なので、
authors = [art.find_all('img')[1].get('alt') for art in articles]
#['東海テレビ', 'CBCテレビ', 'CBCテレビ', ....]とすれば、トップ記事から順に制作会社が得られます。
記事のURLと投稿日時も得る
URLは、a タグの href が持ちます。これも、get を用いて、
print(articles[0].find('a').get('href'))
#/article/99bb4301-2735-4054-8054-5592dc2d5f7b日時はトップ記事では、
print(articles[0].find('div',class_="date_3H64D").text)
# 02.22(月)20:07それ以降の記事では
print(articles[1].find('p').text)
#02.22(月)19:16とこんな感じで情報を得られます。
全ての情報を辞書のリストでまとめて、csvファイル形式に
ここまで、記事名、記事制作会社、日時、url の得方を見ました。
これらを記事それぞれで辞書に纏めて、その辞書のリストを作ります。
辞書はこんな感じです。
dic = {'title':title,
'date':date,
'author':author,
'url':url}この辞書を記事一つ一つに対して作り、article_list で一つに纏めます。
ここまでの処理を、ライブラリインポートからまとめると。。
from bs4 import BeautifulSoup as bs
import requests
import pandas as pd
from pprint import pprint
url = 'https://locipo.jp/article'
res = requests.get(url)
soup = bs(res.text)
articles = soup.find_all('article')
article_list = []
for i , article in enumerate(articles):
if i == 0:
title = article.find('h2').text
date = article.find('div',class_="date_3H64D").text
else:
title = article.find('h3').text
date = article.find('p').text
author = article.find_all('img')[1].get('alt')
url = article.find('a').get('href')
dic = {'title':title,
'date':date,
'author':author,
'url':url}
article_list.append(dic)
print(len(article_list)) # 20articles を for 文で回していますが、トップ記事は他の記事と少し体裁が異なるため、条件分岐を持たせた処理を行います。
辞書がちゃんとできているかは、pprint というライブラリを用いると見やすいです。
from pprint import pprint
pprint(article_list[:2])
'''
[{'author': '東海テレビ',
'date': '02.22(月)20:07',
'title': '勝負強さは健在…球界最年長の中日・福留がDeNAとの二軍練習試合で2安打2打点 石川昂弥も猛アピール',
'url': '/article/99bb4301-2735-4054-8054-5592dc2d5f7b'},
{'author': 'CBCテレビ',
'date': '02.22(月)19:16',
'title': '成人式・嫁入り…思い出の着物を再利用\u3000世界でただ一つの「マイお雛様」',
'url': '/article/20e7beb6-0cc6-40fa-829d-6caa2803e957'}]
'''あとは、この辞書のリストを pandas を用いてデータフレームに変換します。
これにより辞書のキーである、title の列、date の列、author の列、、といった形式になります。
この変換を行うことで csv ファイル形式で保存できます。
data = pd.DataFrame(article_list)
data.head(3)
.head メソッドで、最初の何行かをみることができます。
しっかりと、title 列、date 列、、、とあります。
最後に、csv 形式で保存します。
data.to_csv('locipo.csv',index=False, encoding='utf-8-sig')引数の index は先の画像の一番左の列の、番号をつけるかつけないかの引数です。
ちなみに、header という引数も指定でき、これは、title や date などの列名を削除するか否かを決めます。
エンコーディング形式は、'utf-8-sig' が無難なよう。これは環境によって適宜決めるのが良いかも。
できたcsvファイルをエクセルで開くと。。
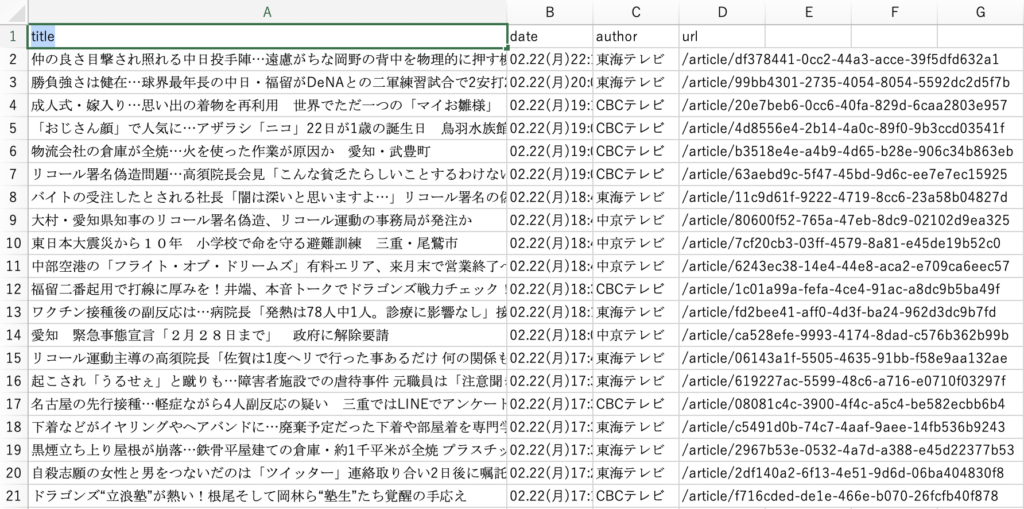
うまくいってそうですね。
まとめ
今回やったこと全部まとめるとこんな感じ。
from bs4 import BeautifulSoup as bs
import requests
import pandas as pd
from pprint import pprint
url = 'https://locipo.jp/article'
res = requests.get(url)
soup = bs(res.text)
articles = soup.find_all('article')
article_list = []
for i , article in enumerate(articles):
if i == 0:
title = article.find('h2').text
date = article.find('div',class_="date_3H64D").text
else:
title = article.find('h3').text
date = article.find('p').text
author = article.find_all('img')[1].get('alt')
url = article.find('a').get('href')
dic = {'title':title,
'date':date,
'author':author,
'url':url}
article_list.append(dic)
data = pd.DataFrame(article_list)
data.to_csv('locipo.csv',index=False, encoding='utf-8-sig')このくらいのスクレイピングならば簡単にできてしまいますね。
サイトの構造を理解するには、少しHTMLとかの知識が必要かもしれませんが、そんなに知識なくとも見てればなんとなくわかってきます。(スクレイピングに必要な知識程度は)
ただし、スクレイピングが禁止されているサイトとかもあるので、利用規約等を少し目を通しておくと安全かもしれません。